
Intro
I've been working with motion capture for a little while now, but never getting much deeper than introductory pipeline things. I've done some retargetting between Maya and Motion Builder, recorded data and cleaned it up, and even wrote a script to help me build a skeleton based on real-time capture (more on that in a later post). But now comes the grand question: what do I do with this information? Usually I like to start with such a query, and work my way through educating myself until I can answer that set question, but this time I was simply exploring just to explore. Which is fine, but it does leave me a bit aimless as I move further into R&D. This has led me to identify other areas of interest, such as animation. Since I was a kid, I've always loved the idea of making music videos with cool chararcters singing along, but I distincting remember lip syncing to be a particular pain when animating in Maya.
Enough exposition, let's talk scripting! As mentioned, I've been interested in making music videos since forever. I knew I wanted to have a character sing along to the music, so naturally lipsyncing would be a concern. I could've very well done it all by hand, but it would not be very "programmer" of me to not try to automate this process. I was inspired by the tool featured in this video:
This led me to discovering Gentle, a forced aligner that essential takes dialogue as an audio file and its transcripts, and aligns phonemes based on a time offset. Gentle is just one forced aligner of many, but at the time of writing it was a very good introduction to the concept and usage. Gentle handles the heavy work of language processing, outputting the phonemes and timings in both CSV and JSON formats. Below is a (very) small subset of example output, to demonstrate how it identifies phonemes in words and accompanying timestamps:
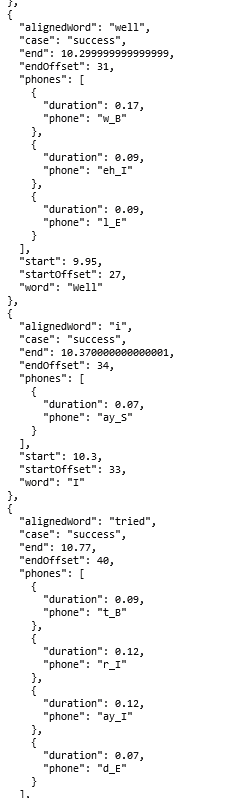
The tool in the video programmatically interfaces with Gentle through HTTP requests, which I simply could not figure out how to do in my solution. This would be optimal addition to my script, but for now I just upload my transcript and audio to the Gentle Demo and save the JSON locally. Upon looking at the output, I knew my script would break into three main parts: receive any input parametes from the user, parse phoneme JSON file, and keyframe the mouth to match the phoneme shapes. For future reference, the JSON is formatted as follows:
{
transcript: ....,
words: [
{
"alignedWord",
"case": "success",
"end",
"endOffset",
"phones": [
{
"duration",
"phone"
},
...
],
"start",
"startOffset",
"word"
},
....
]
}
Part I: Input Parameters
At it's current iteration, there are 7 input parameters: the attribute name for the mouth shape, and 5 indecies representing the sprite to be used for that phoneme, and the JSON file generated by Gentle. This assumes that the mouth shapes are an image sequence for the sake of simplification.
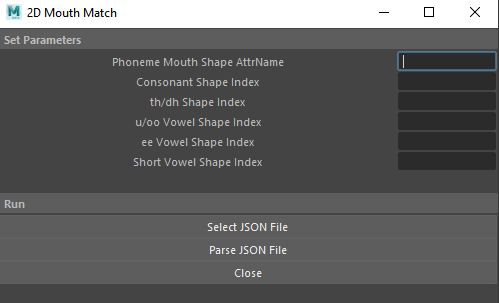
Going forward I would add more nuanced phonemes of course, but this was a good number to start with. When I first started this project, it was acutally only 3 shapes, so an extra 2 made a big difference (which I'll show a bit later). As for functionality, the values of each field are pushed to a 'mouthArray,' where the values at index 0-4 are the sprite number to be used for that phoneme. The indecies are as follows: 0 for consonants, 1 for th/dh, 2 for u/oo/w, 3 for ee/ey/t, and 4 for miscellaneous vowels (this will be replaced and expanded on in later versions). For example, my th/dh sprite is mouth3.png, so I put a '3' at mouthArray[1]. Confusing? Maybe, but bear with me!
Honestly the hardest part of this was writing GUI in Maya. Luckily the interface is pretty simple, but it was still way more trouble than it needed to be.
Parts II & III: Parsing Input
Now we have all necessary info from the user, so let's do something with the data. The ultimate result is to automatically keyframe at the appropriate times with match mouth shapes. Before getting into the actual parsing, let's assign sounds to the indecies provided by the user. For this I made a new function called 'createKeys' that takes in a phoneme. This function simply returns the appropriate value defined by the user based on the provided sound. Usin my example from above, it the phoneme is 'th' or 'dh,' the function returns the value at mouthArray[1], as defined by the user (and we've already established that index 1 holds the value for th/dh sounds).
The first thing I do is read the file provided by the user and load it as JSON. Then I get the 'words' part of the object in order to start iterating. For every word, I first check the 'case,' which states it that word was successfully aligned. If not, I just ignore it. Otherwise, we can get into the meat of the function. The first major component needed is the start time of the word, which is simply accessed by the 'start' property of the word object. I store this time in a variable called 'start,' and create another variable called 'newTime' set equal to 'start' (to be used later for calculating offsets).
Next we iterate through each phoneme (called 'phones' in this object). Phonemes are formatted like so: xx_y, where xx is the "main" sound of the current phone. I'm only working with the first part of the phoneme, i.e. the characters before the underscore. We can now pass this phoneme into the 'createKeys' function defined earlier and set it to a variable. Now all that's left for the keyframe is setting it using the provided attribute name and new value, like so:
cmds.setKeyframe(value=shape, attribute=mouthAttrName, time='{:2.4}sec'.format(newTime))
Now all that's left is updating the time for the next phoneme. This part took me an embarrassingly long time to figure out, after getting thrown off by all of the offsets provided in the JSON. To get the new time, we just need to add the current phoneme's duration (provided by the 'duration' property of the object) to the 'start' time we set earlier.
And that's all for this script! A little over 100 lines, so not too bad at all. Now for some comparisons (featuring my very silly and cute marshmellow man that I made in 5 minutes):
The idea of forced alignment is still very new to me, and at the time of writing I'm still looking for better ways to integrate it into the pipeline. The audio used in this demo is also not ideal (you can see some of the syncing issues a bit later in the audio), as the aligner works best with spoken word and dialogue rather than songs. My current workaround is to record a spoken version of the song synced with the original timings, and just use that to generate the JSON instead. This has given me fairly clean results, especially compared to above. Either way I think this is a solid start, and has lots of potential to grow.
Thanks again for reading, see you next time!